本文仅作为学习目的,一切内容均不构成任何投资意见或建议, 投资有风险入市需谨慎
子查询
子查询(Sub Query)是嵌套在一个Query中的Query,子查询会返回一个完整的数据集供外层查询
select count(*) as blockchain_count,
sum(token_count) as total_token_count,
avg(token_count) as average_token_count,
min(token_count) as min_token_count,
max(token_count) as max_token_count
from (
select blockchain, count(*) as token_count
from tokens.erc20
group by blockchain
)
公共表表达式With
公共表表达式,即CTE(Common Table Expression),是一种在SQL语句内执行(且仅执行一次)子查询的好方法。数据库将执行所有的WITH子句,并允许你在整个查询的后续任意位置使用其结果。
通过with as 可以构建一个子查询,把一段SQL的结果变成一个’虚拟表’(可类比为一个视图或者子查询),接下来的SQL中可以直接从这个’虚拟表’中取数据, 也能提高SQL的逻辑的可读性,也可以避免多重嵌套。
-- CTE的定义方式为with cte_name as ( sub_query )
with blockchain_token_count as (
select blockchain, count(*) as token_count
from tokens.erc20
group by blockchain
)
select count(*) as blockchain_count,
sum(token_count) as total_token_count,
avg(token_count) as average_token_count,
min(token_count) as min_token_count,
max(token_count) as max_token_count
from blockchain_token_count
-- 按日期查询孙哥eth转账数量与价值
with transactions_info as --通过with as 建立子查询命名为transactions_info
(
select block_time, transactions_info.stat_minute as stat_minute,
from, to, hash, eth_amount, price, eth_amount* price as usd_value
from
(
select block_time, date_trunc('minute',block_time) as stat_minute,
from, to, hash, value / power(10,18) as eth_amount --通过将value除以/power(10,18)来换算精度,18是以太坊的精度
from ethereum.transactions
where block_time > '2022-01-01'
and from = lower('0x3DdfA8eC3052539b6C9549F12cEA2C295cfF5296')
and value / power(10,18) > 1000
order by block_time
) as transactions_info
left join
(
--prices.usd表里存的是分钟级别的价格数据
select date_trunc('minute',minute) as stat_minute,
price
from prices.usd
where blockchain = 'ethereum'
and symbol = 'WETH'
)price_info
on transactions_info.stat_minute = price_info.stat_minute --left join关联的主键为stat_minute
)
select date_trunc('day',block_time) as stat_date,
sum(eth_amount) as eth_amount,
sum(usd_value) as usd_value
from transactions_info --从子查询形成的‘虚拟表’transactions_info中取需要的数据
group by 1
order by 1
自定义参数
with contract_address (address, name) as (
values
('0xb136707642a4ea12fb4bae820f03d2562ebff487', 'The DAO'),
('0xc5424b857f758e906013f3555dad202e4bdb4567', 'seth_swap (curvefi)'),
('0xdc24316b9ae028f1497c275eb9192a3ea0f67022', 'steth_swap (curvefi)')
)
聚合函数
数学统计
select
sum(value / power(10,18)) as value --对符合要求的数据的value字段求和
,max(value / power(10,18)) as max_value --求最大值
,min(value / power(10,18)) as min_value--求最小值
,count(hash) as tx_count --对符合要求的数据计数,统计有多少条
,count(distinct to) as tx_to_address_count --对符合要求的数据计数,统计有多少条(按照去向地址to去重)
from ethereum.transactions
where block_time > '2022-01-01'
and from = lower('0x3DdfA8eC3052539b6C9549F12cEA2C295cfF5296') --限制孙哥的钱包,这里用lower()将字符串里的字母变成小写格式(dune数据库里存的模式是小写,直接从以太坊浏览器粘贴可能大些混着小写)
and value / power(10,18) > 1000
时间统计
-- 把粒度到秒的时间转化为天/小时/分钟(为了方便后续按照天或者小时聚合)
select
block_time --transactions发生的时间
,date_trunc('hour', block_time) as stat_hour --转化成小时的粒度
,date_trunc('day', block_time) as stat_date --转化成天的粒度
,date_trunc('week', block_time) as stat_minute--转化成week的粒度
,from
,to
,hash
,value / power(10,18) as value --通过将value除以/power(10,18)来换算精度,18是以太坊的精度
from ethereum.transactions
where block_time > '2021-01-01'
and from = lower('0x3DdfA8eC3052539b6C9549F12cEA2C295cfF5296')
and value / power(10,18) >1000
order by block_time
分组聚合
如果不分组,那默认所有的数据都是同一组;
分组group by需要聚合函数, 分组之后,相同字段内容会组成一组
select date_trunc('day',block_time) as stat_date --用date_trunc函数将block_time转化为只保留日期的格式
,sum(value / power(10,18)) as value --对符合要求的数据的value字段求和
from ethereum.transactions
where block_time > '2022-01-01'
and from = lower('0x3DdfA8eC3052539b6C9549F12cEA2C295cfF5296')
and value / power(10,18) > 1000
group by 1 --按照stat_date去分组,stat_date是用 'as'对date_trunc('day',block_time)取别名
order by 1 --按照stat_date去排序
分组条件
分组的时候要使用having, 与where类似
with nft_trade_details as ( --获取交易的买入卖出方详细信息表,卖出方是负数,买入方是
select seller as trader,
-1 * number_of_items as hold_item_count
from nft.trades
where nft_contract_address = '0xed5af388653567af2f388e6224dc7c4b3241c544'
union all
select buyer as trader,
number_of_items as hold_item_count
from nft.trades
where nft_contract_address = '0xed5af388653567af2f388e6224dc7c4b3241c544'
),
nft_traders as (
select trader,
sum(hold_item_count) as hold_item_count
from nft_trade_details
group by trader
having sum(hold_item_count) > 0
order by 2 desc
),
nft_traders_summary as (
select (case when hold_item_count >= 100 then 'Hold >= 100 NFT'
when hold_item_count >= 20 and hold_item_count < 100 then 'Hold 20 - 100'
when hold_item_count >= 10 and hold_item_count < 20 then 'Hold 10 - 20'
when hold_item_count >= 3 and hold_item_count < 10 then 'Hold 3 - 10'
else 'Hold 1 or 2 NFT'
end) as hold_count_type,
count(*) as holders_count
from nft_traders
group by 1
order by 2 desc
),
total_traders_count as (
select count(*) as total_holders_count,
max(hold_item_count) as max_hold_item_count
from nft_traders
)
select *
from nft_traders_summary
join total_traders_count on true
窗口函数
窗口函数对于处理任务很有用,例如计算移动平均值、计算累积统计量或在给定当前行的相对位置的情况下访问行的值。窗口函数的常用语法格式:
function OVER window_spec
其中,function可以是排名窗口函数、分析窗口函数或者聚合函数。over是固定必须使用的关键字。
window_spec部分又有两种可能的变化:
partition by partition_feild order by order_field表示先分区再排序order by order_field,表示不分区直接排序。
除了把所有行当作同一个分组的情况外,分组函数必须配合 order by来使用。
Rank函数
![]()
row_number()
row_number将每个窗口行从1开始编号
有一组Token地址,需要计算并返回他们最近1小时内的平均价格。
考虑到Dune的数据会存在一到几分钟的延迟,如果按当前系统日期的“小时”数值筛选,并不一定总是能返回需要的价格数据。
相对更安全的方法是扩大取值的时间范围,然后从中筛选出每个Token最近的那条记录。这样即使出现数据有几个小时的延迟的特殊情况,我们的查询仍然可以工作良好。
with latest_token_price as (
select date_trunc('hour', minute) as price_date, -- 按小时分组计算
contract_address,
symbol,
decimals,
avg(price) as price -- 计算平均价格
from prices.usd
where contract_address in (
'0xdac17f958d2ee523a2206206994597c13d831ec7',
'0x2260fac5e5542a773aa44fbcfedf7c193bc2c599',
'0xc02aaa39b223fe8d0a0e5c4f27ead9083c756cc2',
'0xa0b86991c6218b36c1d19d4a2e9eb0ce3606eb48',
'0x7fc66500c84a76ad7e9c93437bfc5ac33e2ddae9'
)
and minute > now() - interval '1 day' -- 取最后一天内的数据,确保即使数据有延迟也工作良好
group by 1, 2, 3, 4
),
latest_token_price_row_num as (
select price_date,
contract_address,
symbol,
decimals,
price,
row_number() over (partition by contract_address order by price_date desc) as row_num -- 按分区单独生成行号
from latest_token_price
)
select contract_address,
symbol,
decimals,
price
from latest_token_price_row_num
where row_num = 1 -- 按行号筛选出每个token最新的平均价格
rank()
dense_rank()
Distribution函数

percent_rank()
cume_dist()
Analytic函数
lead() + Lag()
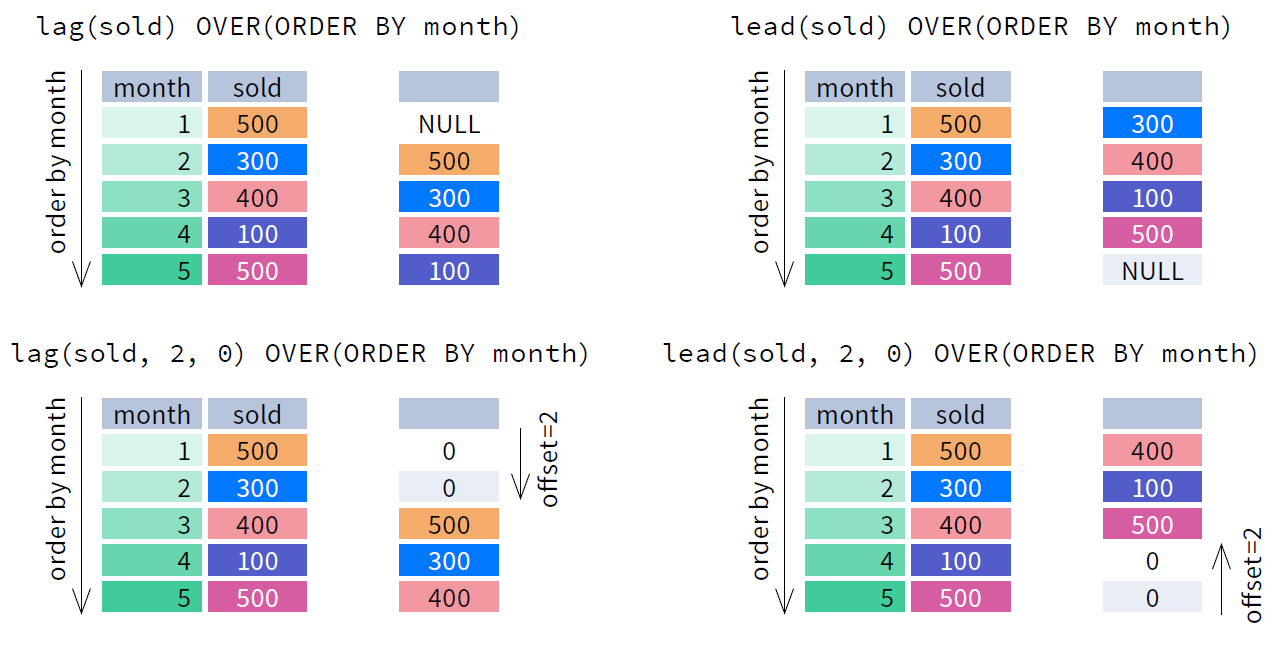
当我们需要将结果集中某一列的值,根下一行(offset=1)的相同列的值进行比较时
Lead()函数从分区内的后续行返回指定表达式的值。其语法为lead(expr [, offset [, default] ] )。Lead函数将列向上移动offset
with post_data as (
select call_block_time,
call_tx_hash,
output_0 as post_id,
vars:profileId as profile_id,
vars:contentURI as content_url,
vars:collectModule as collection_module,
vars:referenceModule as reference_module
from lens_polygon.LensHub_call_post
where call_success = true
union all
select call_block_time,
call_tx_hash,
output_0 as post_id,
vars:profileId as profile_id,
vars:contentURI as content_url,
vars:collectModule as collection_module,
vars:referenceModule as reference_module
from lens_polygon.LensHub_call_postWithSig
where call_success = true
),
-- 返回发帖最多的50个账号
top_post_profiles as (
select profile_id,
count(*) as post_count
from post_data
group by 1
order by 2 desc
limit 50
)
-- 对比这些账号发帖数量的差异
select row_number() over (order by post_count desc) as rank_id, -- 生成连续行号,用来表示排名
profile_id,
post_count,
lead(post_count, 1) over (order by post_count desc) as post_count_next, -- 获取下一行的发帖数据
post_count - (lead(post_count, 1) over (order by post_count desc)) as post_count_diff -- 计算当前行和下一行的发帖数量差
from top_post_profiles
order by post_count desc
当我们需要将结果集中某一列的值,根上一行(offset=1)的相同列的值进行比较时
Lag()函数从分区内的后续行返回指定表达式的值。其语法为Lag(expr [, offset [, default] ] )。Lag函数将列向下移动offset
-- 使用Lag()函数来计算出每天相较于前一天的变化值
with pool_details as (
select date_trunc('day', evt_block_time) as block_date, evt_tx_hash, pool
from uniswap_v3_ethereum.Factory_evt_PoolCreated
where evt_block_time >= now() - interval '29 days'
),
pool_summary as (
select block_date,
count(pool) as pool_count
from pool_details
group by 1
order by 1
)
select block_date,
pool_count,
lag(pool_count, 1) over (order by block_date) as pool_count_previous, -- 使用Lag()函数获取前一天的值
pool_count - (lag(pool_count, 1) over (order by block_date)) as pool_count_diff -- 相减得到变化值
from pool_summary
order by block_date
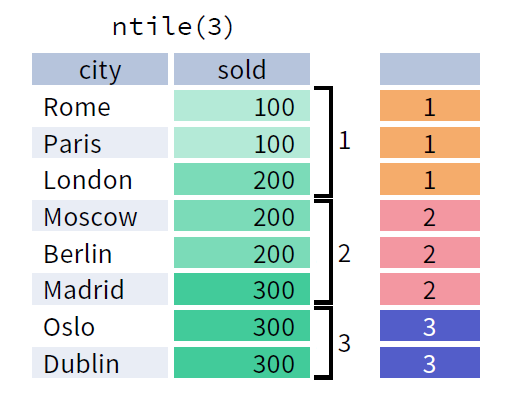
ntile()
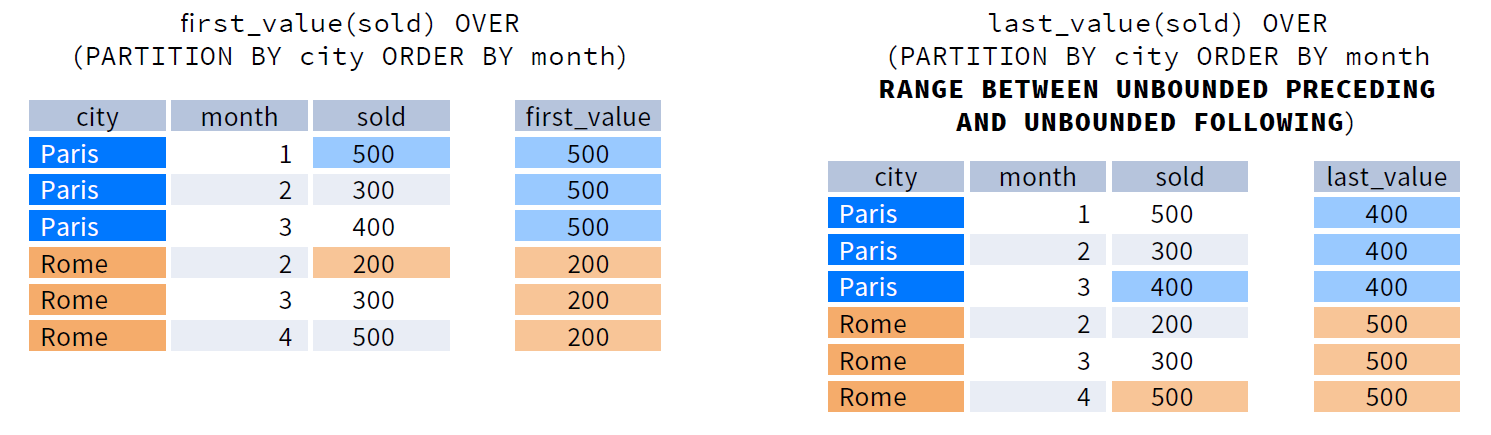
first_value() + last_value()
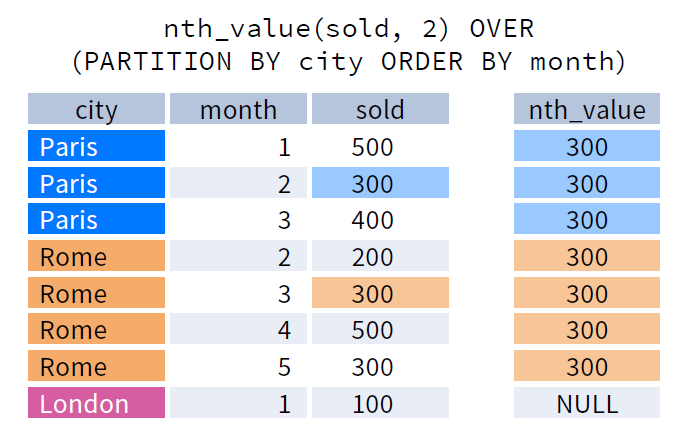
nth_value()
Aggregate函数
聚合函数由avg(), count(), max(), min(), sum()等
-- 统计lens协议用户与交易+累计用户与累计交易
with daily_count as (
select date_trunc('day', block_time) as block_date,
count(*) as transaction_count,
count(distinct `from`) as user_count
from polygon.transactions
where `to` = '0xdb46d1dc155634fbc732f92e853b10b288ad5a1d' -- LensHub
and block_time >= '2022-05-16' -- contract creation date
group by 1
order by 1
)
select block_date,
transaction_count,
user_count,
sum(transaction_count) over (order by block_date) as accumulate_transaction_count,
sum(user_count) over (order by block_date) as accumulate_user_count
from daily_count
order by block_date
集合项
如果你想将查询结果集中每一行数据的某一列合并到一起,可以使用Collect_List()函数。
如果只需要唯一值,可以使用Collect_Set()函数
select collect_list(contract_address) from
(
select contract_address
from ethereum.logs
where block_time >= current_date
limit 10
) as t